笔记来源
本文内部图片大多来自课程课件,侵权请告知1979409875@qq.com
编译和解释
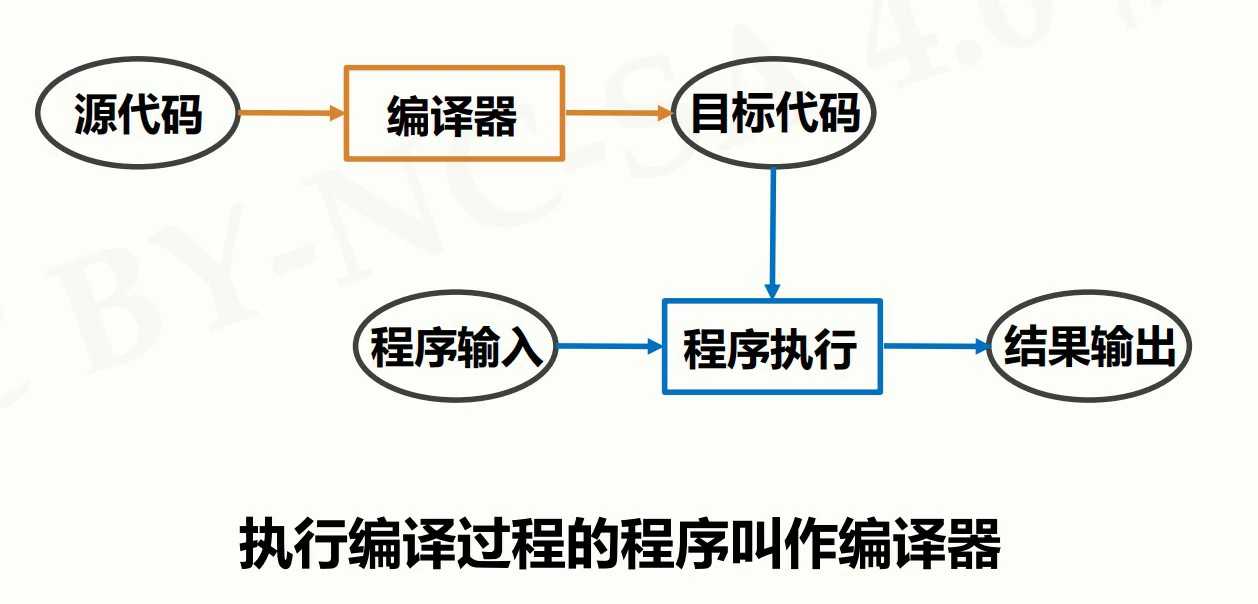
编译
将源代码一次性转换成目标代码的过程
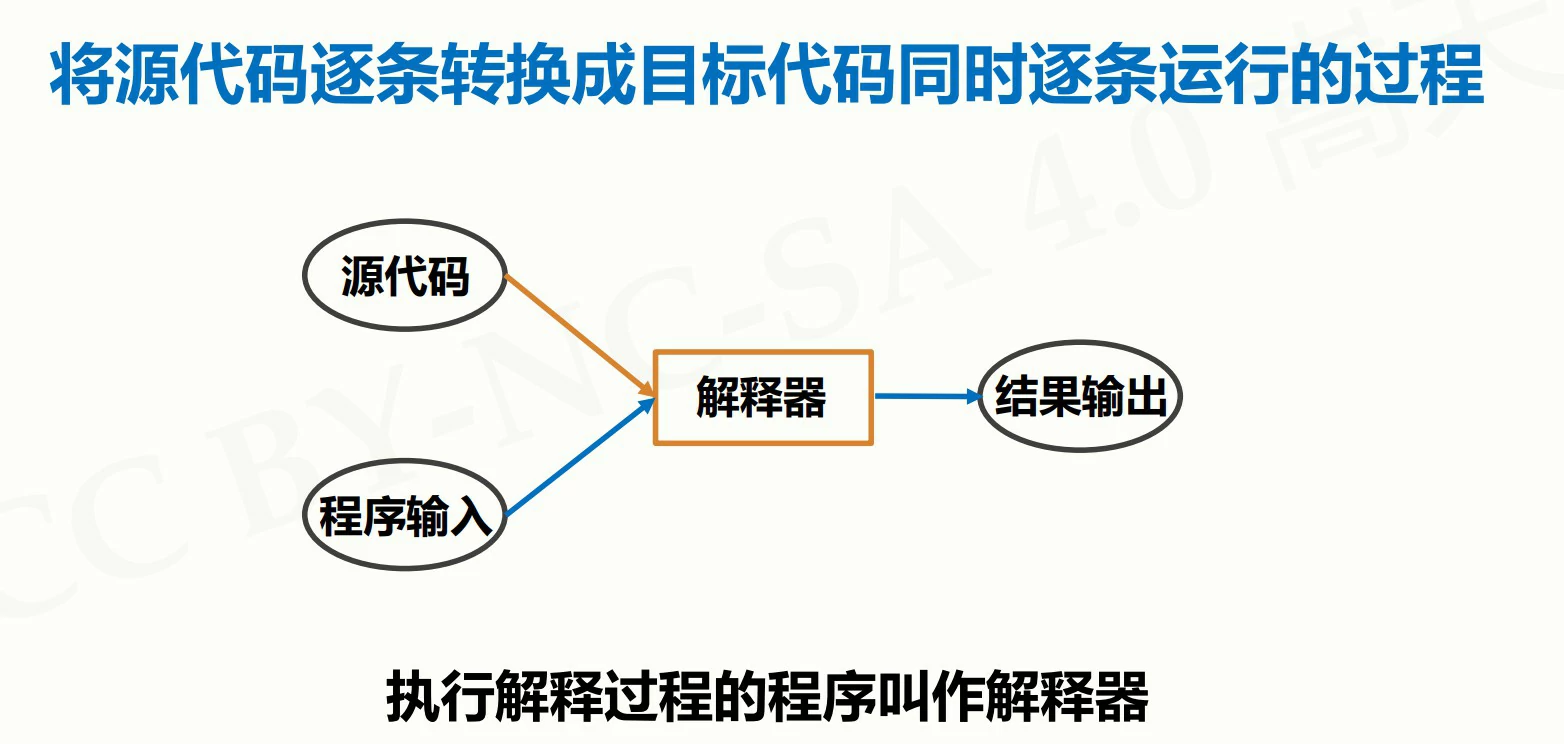
解释
将源代码逐条转换成目标代码同时逐条执行的过程(类似同声传译)
程序的编写方法and思想
IPO
I:Input 程序的输入(文件,网络,控制台,交互界面,内部参数)
P: Proce 对于输入数据的处理,即算法,是一个程序的灵魂所在
O: Output 结果的输出(控制台,图形,网络,文件,内部参数)
IPO思想是编写程序的基本思想,根据用户的输入和所需的输出,进行主体程序的设计和编写,是最简单粗暴的思路。
代码复用
将代码看作一种可以重复使用,互相共享的“资源”。
代码抽象化:使用函数,对象等方法对代码赋予更高级别的定义
模块化设计
通过函数或对象封装将程序划分为模块及模块间的表达,然后通过各个模块之间的相互配合完成主任务
程序部分间的关系分为紧耦合和松耦合两种,模块内部应紧耦合,模块之间应松耦合
python开发环境
python基本开发环境IDLE
python官方提供,适用于小规模程序开发
优点:轻量级,使用灵活;功能丰富,拥有众多标准库以及第三方库可供使用。
python高级开发环境VSCode
配置该环境时要先布局IDLE,后下载VSCode下载地址
python的计算生态
标准库+第三方库
标准库:随解释器直接安装到操作系统中的功能模块
第三方库:需要经过安装才能使用的功能模块
两种编程方式
交互式:对每个输入语句立即运行结果
文件式:代码在py文件中编写完成后一次性进行运行,是编程的主要方式
程序的格式框架
缩进:一行代码开始前的空白部分,用于指出程序的层次结构;是语法的一部分,缩进错误程序也会报错;一个程序中的缩进一般一致,统一为1个Tab或4个空格
注释:不被程序执行的辅助性文字,用于提高代码的可读性;若单行则以#开头,若多行则以’‘‘开头和结尾
命名与保留字
变量:程序中用于保存和表示数据的占位符号
命名:用=将变量和标识符关联起来的过程,命名要遵循许多规则,如:可为大小写字母,数字,下划线和中文字符或其组合;大小写敏感;首字符不能为数字;不与保留字相同
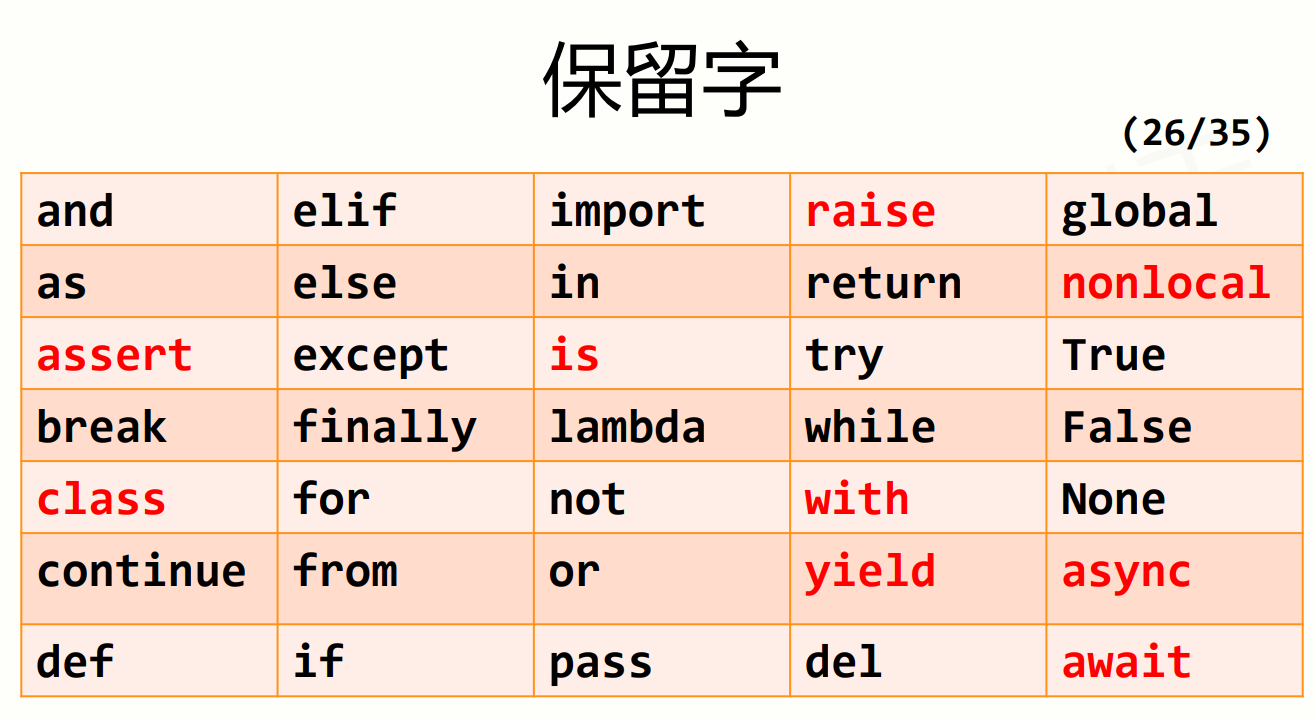
保留字:被编程语言内部定义并保留使用的标识符。python中有35个保留字,它们分别为以下图片中所示
库引用
使用import保留字完成引用
基本用法:import<库名>
<库名>.<函数名>(<函数参数>)
拓展用法
1.from <库名> import <函数名>
2.from <库名> import*
<函数名>(<函数参数>)
此种方法会出现函数重名的问题
3.import <库名> as <库别名>
<库别名>.<函数名>(<函数参数>)
此种方法适用于外部库的原库名较为繁琐的情况,可以达到提高编程效率的效果
数字类型
整数类型
可正可负,无取值范围的限制
拥有多种进制;其中二进制以0b或0B开头,八进制以0o或0O开头,十六进制以0x或0X开头
int(x) 可将x转化为整数类型,同时直接舍弃小数部分
浮点数类型
它与数学中实数的概念相同
浮点数的取值范围与小数精度都存在限制。取值范围数量级约为±10的307次方,而精度数量级为10的-16次方。
float(x) 可将x转化为浮点数类型
由于浮点数类型以53位二进制表示小数部分,故两个浮点数运算过程中存在不确定尾数,导致结果与真实值不同,可以用round()函数进行四舍五入
浮点数类型可以采用科学计数法来表示,使用e或E来作为幂的符号,以10为基数
|
|
复数类型
与数学中复数的概念一致
eg. z = 1.23e-4 + 5.6e + 89j
complex(x) 可将x转化为复数,增加虚数部分
|
|
数值运算
数值运算操作符
|
|
二元操作增强赋值操作符

数值运算函数
|
|
数字类型关系
不同数字类型间可以进行混合运算,生成“最宽”的类型
整数 < 浮点数 < 复数
字符串类型
由0个或多个字符组成的有序字符序列,在最外围被一对单引号或双引号包裹
由一对单引号或双引号只可表示单行字符串,而由一对三单引号或三双引号可以表示多行字符串
字符串中每一个元素的位置有两种序号表示,分别为正向递增序列(从左侧起由0开始定位)和反向递减序列(从右侧起由-1开始定位)
字符串的使用
索引:返回字符串中单个字符 <字符串>[M]
切片:返回字符串中一段字符子串 <字符串>[M:N:K](其中K表示步长,K值为-1时表示对字符串进行逆序输出)
转义符(\)
转义符的使用可以使特定字符失去原来的特殊功能,而表达其字符的本意
转义符还可以与一些字母进行搭配使用,从而表达一些不可打印的含义,如:"\b"表示回退,"\n"表示换行,即光标移动到下行首,"\r"表示回车,即光标移动到本行首
字符串操作符

字符串处理函数
|
|
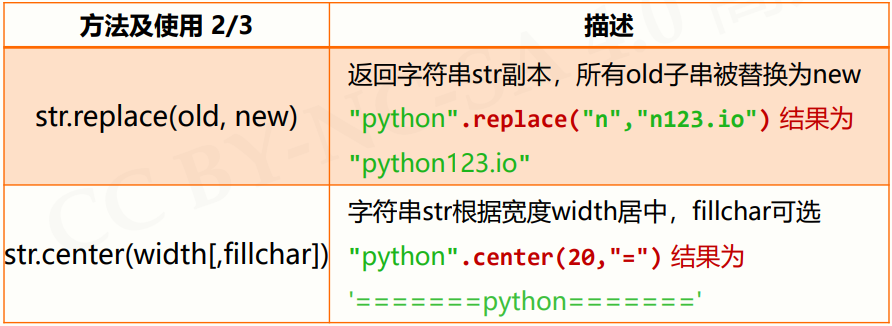
字符串处理方法


字符串类型的格式化
字符串格式化用到.format()方法
<模板字符串>.format(<逗号分隔的参数>)



组合数据类型
集合类型
集合定义
集合是多个元素的无序组合
与数学中的集合概念一致,集合中的元素存在无序性,互异性,确定性
因为要保证集合中的每个元素都唯一确定,故集合中的元素不可更改
集合用大括号{}来表示,集合内的元素用逗号来分隔
建立集合类型可用{}或set()函数,但建立空集合时,必须使用set()函数
集合操作符
|
|
集合的处理方法
|
|
集合类型应用
包含关系的比较,数据去重(由于集合中的元素具有互异性)
序列类型
序列定义
序列类型是具有先后关系的一组元素,元素间由序号引导,通过下标访问特定的元素
序列类型中的下标有两种,分别为正向递增序号(从0开始)和反向递减序号(从-1开始)
序列中的元素类型可以不相同,如字符串类型和整数类型可以同时存在于一个序列中
序列处理函数和方法
|
|
元组类型
元组定义
元组类型是序列类型的一种扩展,和集合类似,一旦创建后就不能被修改
使用小括号() 或 tuple()函数来创建,元素之间要用逗号分隔开来
元组类型的操作与序列类型的操作基本相同
若不希望数据被改变,可将数据转化为元组类型
列表类型
列表定义
列表类型也是序列类型的一种扩展,与元组不同,它创建后可以随意修改
使用方括号[] 或 list()创建,元素间用逗号分隔
列表中的各元素类型可以不同,无长度限制
列表类型的操作函数和方法
|
|
字典类型
字典定义
要使用字典类型,首先要理解“映射”
映射是一种键(索引)和值(数据)的对应,就像取快递时,根据快递单号能够找到自己的快递一样
字典类型是“映射”的具体体现,它是键值对的集合,键值对之间没有顺序
采用大括号{} 或 dict()创建,键值对用冒号表示
字典类型的用法
|
|
字典处理函数和方法
|
|
程序的结构
程序的分支结构
if系列语句
if系列语句是用于控制程序分支结构的语句,if语句可以单独使用,构成单分支结构,还可以与else,elif配合使用,构成二分支结构,多分支结构
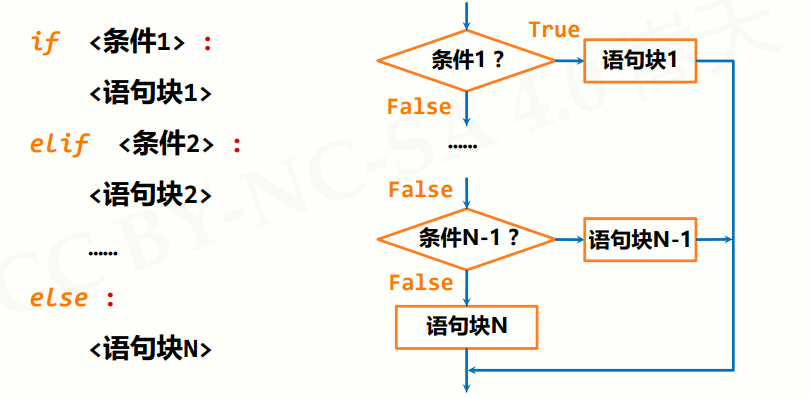
条件判断及组合
条件判断主要用>,<,=等操作符来体现,其中相等用==来表示,不相等用!=来表示
条件组合用and,or,not三个保留字来表示,x and y表示x和y需要同时满足该语句才为真,x or y表示x与y满足一个整条语句就为真,not x表示x为假时该语句才为真
程序的异常处理
用try和except关键字来进行异常处理



程序的循环结构
按照一定次数或条件执行的一组语句
for循环(遍历循环)
由保留字for和in构成,完整遍历所有元素后结束
|
|
遍历结构可以是字符串,列表,文件等等,每次循环都从结构中获取一个元素放入循环的变量当中
for循环常常与range()函数搭配使用
|
|
range(M,N,K)产生M~N-1之间,步长为K的整数序列,其中M,K可省略
while循环(无限循环)
由while关键字构成的循环,每次执行循环的时候都会判断条件是否成立,条件不成立时循环立刻结束
|
|
循环控制保留字
break保留字表示跳出并结束当前整个循环,执行循环后的语句(tip:break保留字仅会跳出当前层循环,多层循环时不会直接结束整个多重循环)
continue保留字表示结束当次循环,继续进行下一个循环
循环的高级用法
循环可以与else关键字结合使用,当循环没有被break语句退出时,执行else语句块,可以将其看作“正常”完成循环的奖励

函数
定义:一段具有特定功能的,可以复用的语句组
作用:降低编程难度和积累复用代码,提高工作效率
|
|
函数只有通过调用以后才会运行,不调用时程序执行时不会运行函数部分
关于参数
可选参数传递:函数定义时可以为某些参数指定默认值,构成可选参数,一般置于非可选参数的后面
可变参数传递:
|
|
参数传递可按照位置或名称两种方式传递
变量
规则1
程序中的变量分为两种,一种为局部变量,即在函数内部进行定义的变量;另一种是全局变量,即在主程序中定义的变量
局部变量在函数执行结束后便被释放,而全局变量在程序执行过程中
规则2
若想在函数内部使用全局变量,需要使用global保留字对变量进行声明
规则3
局部变量为组合数据类型且在函数中未真实创建时,视为全局变量
方法
“方法”特指"<a>.<b>()“风格中的函数”<b>()"
方法本身也是函数的一种,但其特殊地与<a>相关
lambda函数
lambda函数是一种匿名函数,即该函数无函数名,使用lambda保留字定义,函数名是返回的结果
该函数大多用于定义简单的,能够在一行内表示的函数


该函数应谨慎使用,它主要被用作一些特定函数或方法的参数
函数递归
函数定义中调用函数自身的方式
函数递归主要有两个关键特征:链条和基例
链条就是计算过程中两个元素之间存在的关系,类似的例子就像等差数列相邻项的公差;基例就是递归函数中不需要再次递归的部分,运算过程中的其他部分是基于它(们)与链条推导出来的
函数递归的实现要依靠分支语句的帮助
基本实例:斐波那契序列,汉诺塔
文件操作
文件的类型
文件是数据的抽象和集合,一共有两种展现形态,分别为文本文件和二进制文件
本质上两种文件都是采用二进制形式储存,只是展示形式不同而已
文本文件是由单一特定编码(如UTF-8)组成的文件,由于存在编码,故可视作存储着的长字符串,适用于txt,py等
二进制文件直接由比特0和1组成,没有统一字符编码,适用于png,avi等
文件的打开和关闭
文件的打开
<变量名> = open(<文件名(包括文件路径和名称)>, <打开模式>)
文件路径是文件在计算机中储存的位置,包括相对路径和绝对路径
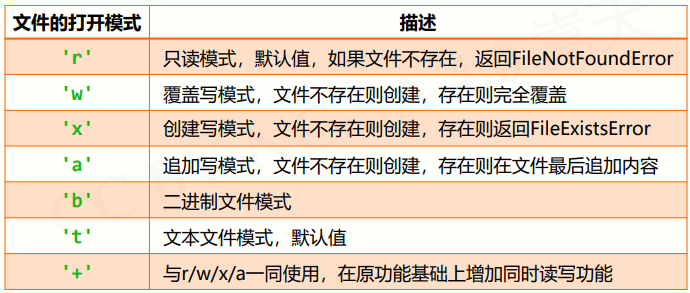
关闭文件用到<变量名>.close()函数
文件内容的读取
|
|
文件内容的写入
|
|
CSV数据储存格式
这是国际通用的一二维数据储存格式,一般以.csv为扩展名
每行一个一维数据,采用(英文半角)逗号分隔,无空行。如果某个元素缺失,逗号仍然要保留
Excel和一般的编辑软件都可以读入或另存为csv文件